[MySQL] explain 이해
페이지 정보
작성자 서방님 댓글 0건 조회 630회 작성일 13-07-31 14:29본문
1. explain의 정의
explain Plan란 SQL을 수행하기전 데이터를 어떻게 가져올 건지에 대한 실행계획을 의미하며
데이터 performance를 확인 하고자 할때 explain Plan 명령어를 사용한다.
2. 사용방법
2.1 ) SELECT 에서 explain 사용하기
select explain을 사용하려면 SELECT 키워드 앞에 explain을 붙여주면된다. 간단하게 user라는 테이블과 author이라는 테이블이 있다라고 할때 두 테이블을 조인한 테이블에 대하여 explain을 주었다.
아래는 두 테이블에 대한 explain 결과이다.
[그림 1]
EXPLAIN SELECT user.user_name, author.authority_seq
ㅠ FROM tb_user_m user JOIN tb_authority_user author ON user.user_seq = author.user_seq ;
explain은 쿼리에 있는 테이블 하나당 한 행씩 출력이 된다.
위에 [그림1] 또한 두개의 테이블을 조인한 결과이기 때문에 두개의 행이 출력되었다.
* 여기서 말하는 테이블은 서브쿼리 일수도 있고, union 결과일 수도 있다.
2.2) SELECT가 아닌 쿼리구문에서 explain 사용하기
select 쿼리에서는 앞에 explain만 붙여줌으로써 실행계획을 확인할 수 있지만 INSERT,UPDATE,DELETE와 같이 입력,수정,삭제와 같은 것들은 실행계획을 확인 할 수 없다.
그렇기때문에 INSERT,UPDATE, DELETE로 작성된 쿼리에서 사용된 칼럼으로 SELECT문으로 재구성시켜줘야한다.
이해하기 좀 어려울 듯해서 아래에 예시를 들어보겠다.
UPDATE tb_user_m SET user_name='najung' ;
라는 update 쿼리가 있다.
위에 나오는 update쿼리구문을
EXPLAIN SELECT user_name FROM tb_user_m ;
으로 바꿔서 실행계획을 확인하는 것이다.
3. explain 컬럼
위 [그림1]을 하나씩 쪼개서 설명해보겠다.
3.1) id 칼럼
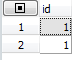
[그림2]
id칼럼은 구문에 따라 순차적으로 번호가 부여된다. 현재 JOIN같은 경우 하나의 쿼리에서 두 테이블이 동시에 실행됬기때문에 모든 행에 1이라는 값이 부여됬지만 union이나 서브쿼리가 구문에 들어있다면 위 예제는 달라진다.
아래는 union을 이용한 쿼리이다.
EXPLAIN
SELECT user_name,user_id FROM tb_user_m UNION SELECT result_code, register_time
FROM tb_login_h
이러한 쿼리를 통해 explain했을 때 결과 값은

[그림3]
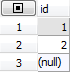
[그림4]
처음에 나온 1이 tb_user_m에 대한 쿼리 열이고 두번째 2는 tb_login_h에 대한 쿼리열이다.
여기서 뒤에 select type 칼럼을 설명하면서 한번 더 이야기 하겠지만,
mysql은 select 쿼리를 간단한 타입과 복잡한 타입으로 설정한다.
복잡한 타입은 유도된 테이블(sub쿼리), union으로서 복잡한 쿼리를 실행할 경우 id가 복잡해진다.
또한 [그림4] union 경우 3.null부분은 mysql에서 union결과가 임시테이블에 저장되었다가 다시 읽혀지는데 임시테이블은 sql에서 나와있지 않아 컬럼이 null을 가진다.
3.2) select_type 칼럼
select_type은 간단한 쿼리인지 복잡한 쿼리인지 를 나타낸다.
[그림 1] 같이 union이나 서브쿼리가 없을 경우 SIMPLE
[그림 3] 같이 union이나 서브쿼리가 있을 경우에는
가장 밖에 있는 부분은 PRIMARY로 표시되고
나머지는 다음과 같다.
3.2.1) SUBQUERY : 쿼리문장의 FROM절이 아닌 SELECT절에 나타나는 서브쿼리인 경우 SUBQUERY라 한다.
3.2.2) DERIVED : FROM절에 있는 서브쿼리를 표시하는데 사용된다.
3.2.3) UNION : UNION을 사용한 쿼리절일 경우 사용된다.
3.2.4) UNION_RESULT : UNION의 결과 값이 임시테이블에 저장되며, 그 임시테이블을 표현할 때 사용된다.
3.3) table 칼럼
table 칼럼은 어떤 테이블에 접근하는지 보여준다. 대부분의 경우 테이블의 이름이나 sql에서 지정해준 ( ex : AS user ) 값을 가진다.
table 컬럼은 간단한 예제는 이해하기 쉬우나 , 복잡한 쿼리같은 경우 이해하기 어렵다.
아래의 예시를 보자
EXPLAIN
SELECT *
FROM
(SELECT cast(@rnum := @rnum+1 as unsigned) AS seq,
union_result.*
FROM (SELECT @rnum := 0) r,
(
(SELECT article_h.regist_time as time ,
article_h.user_id as id,
article_h.user_institution as institution,
article_h.user_position as position,
article_h.user_name as name,
article_h.register_ip as ip,
concat(article_h.module_name, ' | ', article_h.article_name, ' | ', article_h.action_name) as action_name
FROM tb_article_h article_h
)
UNION ALL
(SELECT login_h.register_time as time,
login_h.user_id as id,
user.user_institution as institution,
code2.code_name AS position,
login_h.user_name as name,
login_h.register_ip as ip,
code.code_name as action
FROM tb_common_code code
INNER JOIN tb_login_h login_h
ON code.code=login_h.result_code,
tb_common_code code2
INNER JOIN tb_user_m user
ON code2.code=user.user_position_code
WHERE user.user_id = login_h.user_id
)
)
union_result
WHERE 1=1
ORDER BY time ASC
) result
WHERE seq BETWEEN 0 AND 10
ORDER BY seq DESC
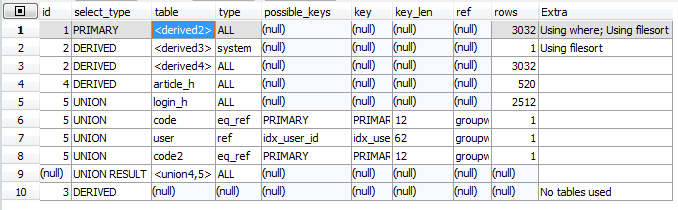
[그림 5]
[그림 5]에 대한 테이블을 설정하자면 이러하다.
1. id 값이 1인 table명은 derived2 이다. 이러한 테이블 명은 id값이 2이고 select_type이 DERIVED인 테이블을 참조하는 테이블이라고 이해하면 된다. 빨간색으로 표시한 부분이 derived2이다.
2. id값이 2인 table명은 derived3 과 derived4 이다.
이하 동문 ...
* 마지막 10행이 이해가 가지않음
3.4) type 칼럼
mysql 메뉴얼에는 조인 방식이라고 나타내고 있으나 테이블에서 행을 어떻게 찾는지 라고 이해하는게 더 쉽다.
type칼럼 종류를 나쁜 방식에서 좋은 방식 순으로 설명하도록 하겠다.
3.4.1) ALL : mysql이 행을 찾기 위해 처음부터 끝까지 스캔해야한다는 것을 의미한다.
3.4.2) INDEX : 인덱스 순서로 스캔 한다는 것을 제외하면ALL과같다. 일반적인 경우 인덱스가 테이블보다 사이즈가 작기 때문에,ALL보다는 빠를 가능성이 높다. (이해가 잘 되지 않음 )
3.4.3) RANGE : 제한된 형태의 인덱스 스캔이다. RANGE스캔경우 인덱스 특정부분에서 시작해서 특정범위에 있는 값을 가지는 행을 반환한다. 키컬럼이 상수와 =, <>, >, >=, <, <=, IS NULL,<=>, BETWEEN 또는 IN 연산에 사용될 때 적용된다.
SELECT * FROM tb_user_m WHERE user_seq = 10; SELECT * FROM tb_user_m WHERE user_seq BETWEEN 10 and 20; SELECT * FROM tb_user_m WHERE user_seq IN (10); SELECT * FROM tb_user_m WHERE user_seq= 10 AND user_seq IN (20);
3.4.4) ref : 어떤 값 하나에 매치되는 행들을 반환해주는 인덱스 접근방식이다. 인덱스에 매치되는 값이 많지 않은 경우 나쁘지 않다. PRIMARY KEY 또는 UNIQUE 인덱스가 아닐 경우에 ref가 사용되며 = 또는 <=> 연산자를 사용해서 비교되는 인덱스된 컬럼에 대해 사용될 수 있다.
SELECT * FROM tb_user_m WHERE user_name='손화정';
SELECT * FROM tb_user_m user, tb_login_h login where user.user_id = login.user_id ;
* 기울림된 쿼리 두개의 차이가 이해가 가지 않음
3.4.5) eq_ref : 테이블에서 찾은 값중 단 하나의 값만 해당 테이블에 존재하는 경우 이런 인덱스 탐색법이 사용된다. 기본키 혹은 unique 인덱스에 비교할 떄 이런 접근 방법을 많이 사용한다. eq_ref는 = 연산자를 사용해서 비교되는 인덱스된 컬럼용으로 사용될 수 있다.
SELECT * FROM tb_authority_user author JOIN tb_user_m user ON user.user_seq = author.user_seq ;
3.4.6) const : 쿼리의 일부를 상수로 대체시킬 수 있을 때 사용한다. const 테이블은 한번 밖에 읽혀지지 않기 때문에 매우 빠르다.const는 PRIMARY KEY 또는 UNIQUE 인덱스의 모든 부분을 상수 값(constant value)과 비교를 할 때 사용된다.
SELECT * FROM tb_user_m WHERE user_seq= 7
3.4.7) system : 무조건 하나의 열만을 가지고 있는 테이블 . 이것은 const의 특별한 경우이다.
3.5) possible_key 칼럼
possible_keys 컬럼은 이 테이블에서 열을 찾기 위해 MySQL이 선택한 인덱스를 가리킨다. 이 possible_key컬럼은 최적화단계에서 시작하기 떄문에 최적화가 끝나는 단계가 진행됨에 따라 쓸모가 없어질 수도 있다.
만일 이 컬럼 값이 NULL이라면, 연관된 인덱스가 존재하지 않게 된다. 이와 같은 경우, 여러분은 WHERE 구문을 검사해서, 이 구문이 인덱스 하기에 적당한 컬럼을 참조하고 있는지 여부를 알아 봄으로써 쿼리 속도를 개선 시킬 수가 있게 된다.
3.6) key칼럼
key 컬럼은 MySQL이 실제로 사용할 예정인 키 (인덱스)를 가리킨다 .
3.7) key_len 컬럼
인덱스 필드가 가질 수 있는 최대의 길이를 출력한다.
3.8) ref 칼럼
키 칼럼에 나와 있는 인덱스에서 찾기 위한 선행 테이블의 어떤 칼럼이 사용되었는지 나타낸다.
3.9) row칼럼
row칼럼 원하는 행을 찾기 위해 얼마나 많은 행을 읽어야 할지 예측값을 의미한다.
tb_user_m에 50명의 회원이 있을 때 tb_user_m에 대한 테이블의 row칼럼은 50이 될 것이다.
3.10) extra칼럼
3.10.1)using index : mysql 테이블에 접근하지 않도록 커버링 인덱스를 사용한다는 것을 알려준다.
*커버링 인덱스란 , 쿼리를 실행시키기 위해 필요한 데이터가 모두 포함된 인덱스를 말한다.
3.10.2)using where : mysql서버가 값을 가져온 뒤 행을 필터링 한다는 것을 의미한다.
3.10.3)using temporary : mysql이 쿼리결과를 정렬하기위해 임시테이블을 사용한다는 것을 의미한다.
3.10.4)using filesort : mysql이 결과의 순서를 맞추기 위해 인덱스 순서로 테이블을 읽는 것이 아니라 외부 정렬을 사용해야한다는 것을 의미한다.
3.10.5)range checked for each record (index map:N) : 적합한 인덱스가 없으므로 각 레코드 조인에서 각 엔덱스들을 재평가한다는 것을 의미한다.
댓글목록
등록된 댓글이 없습니다.
