웹사이트 트래픽 잡아먹는 로봇 robots.txt 쉽게 해결하기
페이지 정보
작성자 서방님 댓글 0건 조회 497회 작성일 16-03-21 11:26본문
트래픽과의 싸움이 계속되고 있습니다.
지난 포스팅들에서 이미 밝혔듯이 XE,GB로 만든 제 사이트의 트래픽 중 90% 이상이 검색봇에 의한 것임을 알았고, 그래서 이 문제를 해결하기 위해서 동분서주 중입니다.
이곳저곳 달려봤자 인터넷 검색이 제가 가진 무기일뿐이지만 말이죠.
그러다가 여러가지 정보들을 알게 되었는데 그 중에 robots.txt 만들기를 쉽게 설정할 수 있는 사이트가 있어서 블로그에 소개해 봅니다.
Robot Control Code Generation Tool사용방법은 간단합니다.
Default 설정에서 모든 검색봇이 들어올지 말지를 allowed와 refused를 통해서 선택합니다.
Crawl-Delay를 통해서 검색봇이 지나가는 시간을 설정할 수도 있고요. Sitemap은 아직 뭘 말하는건지 잘 모르겠군요.
그리고 특정 검색로봇이 사이트로 진입하는 것을 허용할 것인지 말 것인지도 설정할 수 있습니다.
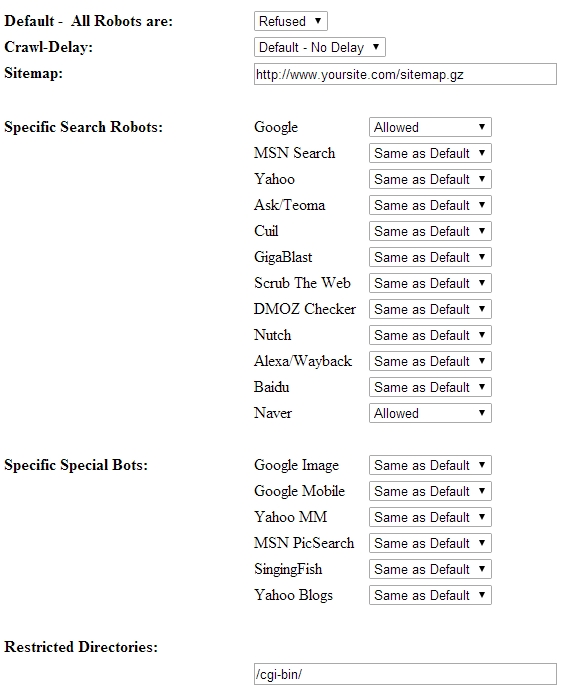
저같은 경우 모든 검색봇이 들어오지 못하게 하였습니다. 하지만 구글과 네이버 검색봇만큼은 들어오게 허용한 방식으로 바꾼거죠.
이렇게 한 이유는 제가 외국인 대상의 사이트가 아니기 때문에 빙이나 야후 등은 검색 안 되도 상관없다고 생각하고요. 네이버가 국내 검색점유율 80% 이상, 구글이 4% 정도 되고 다음만 따로 추가하면 얼추 국내에서 나오는 검색엔진은 다 챙긴 셈이니까요.
저렇게 만들어 둔 뒤에 Creat Robots.txt를 눌러주면 아래의 코드들이 좌르륵 생겨납니다.

그런데 다음봇은 저기서 설정할 수 없기 때문에 따로 daumoa(다음 검색봇의 이름)은 직접 입력하였습니다.
지금까지 제대로 된 robots.txt인지 확인해보고 싶다면 Robots.txt Checker를 이용하면 편하더군요.

이 사이트에 자신의 사이트주소/robots.txt를 입력하면 robots.txt 코드를 제대로 작성했는지 확인해줍니다.
저같은 경우 disallow:와 user-agent 사이에 엔터를 치지 않은게 오류가 떠서 엔터를 쳐서 떨궈 놓았습니다.
그러니까
<pre style="white-space: pre-wrap; word-wrap: break-word;"></pre> <pre style="white-space: pre-wrap; word-wrap: break-word;">User-agent: NaverBot Disallow: User-agent: Yeti Disallow: User-agent: googlebot Disallow: User-agent: daumoa Disallow: User-agent: * Disallow: / </pre>
위의 상태였는데 다음과 같이 바꾼거죠.
User-agent: NaverBot Disallow: User-agent: Yeti Disallow: User-agent: googlebot Disallow: User-agent: daumoa Disallow: User-agent: * Disallow: /
이걸 메모장에 입력한 뒤에 루트 폴더 내에 집어 넣어놓았습니다. 제발 트래픽이 좀 줄어들었으면 좋겠군요.
댓글목록
등록된 댓글이 없습니다.
